6.5840官网链接:https://pdos.csail.mit.edu/6.824/labs/lab-mr.html
一、概述
MapReduce: Simplified Data Processing on Large Clusters提出了一种针对大数据处理的编程模型和实现,使得编程人员无需并行和分布式系统经验就可以轻松构建大数据处理应用。该模型将大数据处理问题拆解为两步,即 map 和 reduce ,map 阶段将一组输入的键值对转化为中间结果键值对,reduce 阶段对中间结果键值对按照相同的键进行值的合并,从而得到最终的结果。
1.1 背景
对于 Google 来说,每天运行的系统会产生大量的原始数据,同时又要对这些原始数据进行加工产生各种衍生数据,虽然大部分数据加工的逻辑都较为简单,然而由于数据量过于庞大,为了在合理的时间内完成数据处理,通常需要将待处理的数据分发到几百或几千台机器上并行计算,这就存在几个问题:
如果每一个数据加工任务都需要独立去解决上述的问题,一方面会使得原本简单的代码逻辑变得庞大、复杂和难以维护,另一方面也是在重复工作。受 Lisp 等其他函数式编程语言中的 map 和 reduce 函数的启发,Google 的工程师们发现大部分的数据处理遵循如下的模式:
对输入的每一条数据应用一个 map 函数产生一组中间结果键值对
对中间结果键值对按照相同的键聚合后,应用 reduce 函数生成最终的衍生数据
因此,Google 的工程师们抽象出了 MapReduce 框架,使得应用开发人员可以专注于计算逻辑实现而无需关心底层运行细节,统一由框架层处理并行、容错、数据分发和负载均衡等系统问题。现在再来看前面提到的问题是如何解决的:
如何使计算可并行:在 map 阶段,对数据分发后,各任务间无依赖,可并行执行;在 reduce 阶段,不同 key 的数据处理间无依赖,可并行执行
如何分发数据:在 map 阶段,可按执行 map 任务的节点数量平均分发(这只是一种可能的策略,具体分发策略见后文描述);在 reduce 阶段,可按 key 相同的数据聚合后分发
如何处理异常:重新执行某个节点上失败的 map 或 reduce 任务作为首要的容错手段
1.2 系统架构与关键流程
在 map 执行阶段,框架会自动将输入数据分为 M 片,从而将 map 任务分发到多台机器上并行执行,每台机器只处理某一片的数据。同样的,在 reduce 阶段,框架首先将中间结果数据根据分片函数(例如 hash(key) mod R)拆分为 R 片,然后分发给 reduce 任务执行,用户可自行指定 R 的值和实现具体的分片函数。
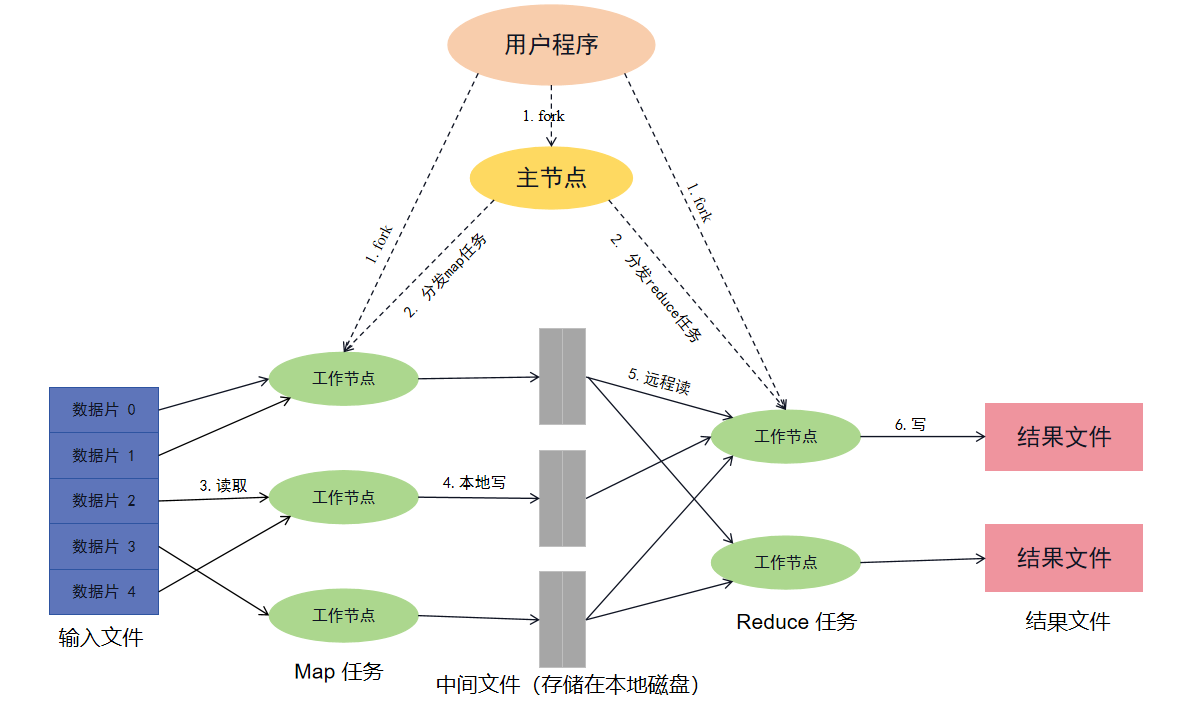
下图展示了 Google 所实现的 MapReduce 框架的整体执行流程:
首先 MapReduce 框架将输入数据分为 M 片,每片数据大小一般为 16 MB 至 64 MB(具体大小可由用户入参控制),然后将 MapReduce 程序复制到集群中的一批机器上运行。
在所有的程序拷贝中,某台机器上的程序会成为主节点(master),其余称为工作节点(worker),由主节点向工作节点分派任务,一共有 M 个 map 任务和 R 个 reduce 任务需要分派。主节点会选择空闲的工作节点分派 map 或 reduce 任务。
如果某个工作节点被分派了 map 任务则会读取当前的数据分片,然后将输入数据解析为一组键值对后传递给用户自定义的 map 函数执行。map 函数产生的中间结果键值对会暂存在内存中。
暂存在内存中的中间结果键值对会周期性的写入到本地磁盘中,并根据某个分片函数将这些数据写入到本地磁盘下的 R 个区,这样相同键的中间结果数据在不同的 map 节点下属于同一个区号,就可以在后续将同一个键的中间结果数据全部发给同一个 reduce 节点。同时,这些数据写入后的地址会回传给 master 节点,master 节点会将这些数据的地址发送给相应的 reduce 节点。
当 reduce 节点接收到 master 节点发送的中间结果数据地址通知后,将通过 RPC 请求根据数据地址读取 map 节点生成的数据。在所有中间结果数据都读取完成后,reduce 节点会先将所有中间结果数据按照键进行排序,这样所有键相同的数据就聚合在了一起。之所以要排序是因为一个 reduce 节点会分发处理多个键下的中间结果数据。如果中间结果数据量太大不足以完全载入内存,则需要使用外部排序。
reduce 节点执行时会先遍历排序后的中间结果数据,每遇到一个新的键就会将该键及其对应的所有中间结果数据传递给用户自定义的 reduce 函数执行。reduce 函数执行的结果数据会追加到当前 reduce 节点的最终输出文件里。
当所有 map 任务和 reduce 任务都执行完成后,master 节点会唤醒用户程序,并将控制权交还给用户代码。
二、代码实现
Lab1 的任务是依托给出的框架,完善src/mr目录下的Coordinator、Worker和Rpc的代码,实现一个简单的MapReduce框架。
代码其实已经给出了一个串行运行的mapreduce,我们需要做的就是借助于rpc将其改为并行的框架,可支持多个线程或机器同时完成一个任务,以提高运行效率。
整体流程:
worker启动一个无限循环,通过rpc向coordinator节点获取任务,然后coordinator通过rpc分配map任务给worker节点,等待worker节点将map任务完成。coordinator在分配任务后会使用协程检测该任务是否在10秒内完成,如果超时则重新分配任务 。worker节点将分配的map任务完成以后,生成对应的中间文件intermediate,将结果返回给coordinator,coordinator接收到结果以后,更新任务状态,主要记录所有的map任务是否完成。coordinator根据worker的回报信息进行判断,如果是map类型则已完成的map任务数量 +1 ,然后判断更新mapFinished。如果是reduce类型,则更新相应的状态,已完成的reduce任务数量 +1 。当所有的map任务都完成以后,即mapFinished状态转变。coordinator会将map获取的中间文件分配给worker节点作为reduce任务的输入,然后worker节点执行reduce任务。
每次完成reduce任务后worker节点向coordinator报告并更新状态,直到所有任务完成,完成mapreduce任务。
2.1 rpc
对于rpc,我其实只需要2种通信4种消息类型即可,一个是用于获取任务,一个是用于报告任务完成情况。GetTaskRequest与GetTaskResponse用于获取任务,ReportStatusRequest与ReportStatusResponse用于报告任务完成情况。coordinator和worker的具体实现进行定义,在代码完成的过程中一步步完善。最后的定义如下:意义都如名字所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 type GetTaskRequest struct { } type GetTaskResponse struct { TaskIdentifier string TaskType int // 0:map 1:reduce 2:sleep MapFileName string ReduceFilesName []string ReduceNumber int } type ReportStatusRequest struct { TaskIdentifier string IntermediateFilesName []string } type ReportStatusResponse struct { }
2.2 coordinator
coordinator 或者说 master 节点,其核心功能是分配任务,并且检测任务是否完成。
1 2 3 4 5 6 type Task struct { name string taskType int mapFileName string reduceFileId int }
name是由一个全局自增的taskIdentifier来标识的,以区别任务,taskType是任务的类型,0表示map任务,1表示reduce任务,2表示Sleep,无任务。
coordinator的定义如下;
1 2 3 4 5 6 7 8 9 10 11 12 type Coordinator struct { // Your definitions here. mapFiles map[string]int // name : status reduceFiles map[int]int // id : status intermediateFiles map[int][]string // id : names taskMap map[string]*Task // taskIdentifier : Task mapFinishedCount int // number of map tasks finished reduceFinishedCount int // number of reduce tasks finished mapFinished bool // all map tasks finished reduceNumber int // number of reduce tasks mutex sync.Mutex }
mapFiles与reduceFiles这两个map是用来记录静态任务的状态的,mapFiles记录map任务的状态,reduceFiles记录reduce任务的状态。status则是需要我们完成的静态任务的状态
1 2 3 4 5 const ( // Status Ready = iota Running Finished )
coordinator主要实现两个函数,一个是用于分发任务的AssignTask,一个是用于检测任务状态的ReportStatus
对于AssignTask,我们仅需遍历mapFiles与reduceFiles,对于处于Ready状态的任务,我们分配给worker,并将其状态改为Running。具体的逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 func (c *Coordinator) AssignTask(args *GetTaskRequest, reply *GetTaskResponse) error { c.mutex.Lock() defer c.mutex.Unlock() reply.MapFileName = "" reply.ReduceFilesName = make([]string, 0) reply.ReduceNumber = c.reduceNumber reply.TaskIdentifier = strconv.Itoa(taskIdentifier) taskIdentifier++ // dont forget ++ if c.mapFinished { for v := range c.reduceFiles { if c.reduceFiles[v] == Ready { c.reduceFiles[v] = Running reply.ReduceFilesName = append(reply.ReduceFilesName, c.intermediateFiles[v]...) reply.TaskType = Reduce newTask := &Task{reply.TaskIdentifier, reply.TaskType, "", v} c.taskMap[reply.TaskIdentifier] = newTask go c.HandleTimeout(reply.TaskIdentifier) return nil } else { continue } } reply.TaskType = Sleep return nil } else { for v := range c.mapFiles { if c.mapFiles[v] == Ready { c.mapFiles[v] = Running reply.MapFileName = v reply.TaskType = Map newTask := &Task{reply.TaskIdentifier, reply.TaskType, reply.MapFileName, -1} c.taskMap[reply.TaskIdentifier] = newTask go c.HandleTimeout(reply.TaskIdentifier) return nil } else { continue } } reply.TaskType = Sleep return nil } }
利用协程处理超时时,我们通过time.Sleep让其睡眠10s,若10s后该Task还在taskMap中,则认定其超时,将其从taskMap中删除,并将其对应的静态任务状态改为Ready,等待重新分配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (c *Coordinator) HandleTimeout(taskId string) { time.Sleep(10 * time.Second) c.mutex.Lock() defer c.mutex.Unlock() if t, ok := c.taskMap[taskId]; ok { if t.taskType == Map { f := t.mapFileName if c.mapFiles[f] == Running { c.mapFiles[f] = Ready } } else { f := t.reduceFileId if c.reduceFiles[f] == Running { c.reduceFiles[f] = Ready } } delete(c.taskMap, taskId) } }
对于ReportStatus,我们需要根据worker汇报的信息进行判断,如果完成的Task是Map,我们需要判断所有的Map任务是否都完成了,并且要将Map生成的中间文件加入到对应的Reduce任务组中,具体逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 func (c *Coordinator) ReportStatus(args *ReportStatusRequest, reply *ReportStatusResponse) error { c.mutex.Lock() defer c.mutex.Unlock() if t, ok := c.taskMap[args.TaskIdentifier]; ok { if t.taskType == Map { f := t.mapFileName c.mapFiles[f] = Finished c.mapFinishedCount++ if c.mapFinishedCount == len(c.mapFiles) { c.mapFinished = true } for _, v := range args.IntermediateFilesName { index := strings.LastIndex(v, "_") reduceId, err := strconv.Atoi(v[index+1:]) if err != nil { log.Fatal(err) } c.intermediateFiles[reduceId] = append(c.intermediateFiles[reduceId], v) } delete(c.taskMap, t.name) return nil } else if t.taskType == Reduce { f := t.reduceFileId c.reduceFiles[f] = Finished c.reduceFinishedCount++ delete(c.taskMap, t.name) return nil } else { log.Fatal("task type is not map and reduce") } } log.Printf("Task %s not found\n", args.TaskIdentifier) return nil }
2.3 worker
worker的主要逻辑:在一个无限循环中,不断向coordinator请求任务,如果coordinator分配了任务,worker就执行该任务,并将执行结果汇报给coordinator。比较简单,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 // Your worker implementation here. for { args := GetTaskRequest{} reply := GetTaskResponse{} call("Coordinator.AssignTask", &args, &reply) if reply.TaskType == Map { intermediateFilesName := HandleMapTask(mapf, reply.MapFileName, reply.ReduceNumber, reply.TaskIdentifier) reportStatusArgs := ReportStatusRequest{reply.TaskIdentifier, intermediateFilesName} reportStatusReply := ReportStatusResponse{} call("Coordinator.ReportStatus", &reportStatusArgs, &reportStatusReply) } else if reply.TaskType == Reduce { HandleReduceTask(reducef, reply.ReduceFilesName) reportStatusArgs := ReportStatusRequest{reply.TaskIdentifier, []string{}} reportStatusReply := ReportStatusResponse{} call("Coordinator.ReportStatus", &reportStatusArgs, &reportStatusReply) } else if reply.TaskType == Sleep { time.Sleep(time.Millisecond * 100) } else { log.Fatal("Unknown task type") } }
HandleMapTask与HandleReduceTask其实就是将串行的map和reduce操作封装一下,比较简单,主要是注意Hints中有提示我们利用json来处理数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 func HandleMapTask(mapf func(string, string) []KeyValue, mapFileName string, reduceNum int, taskId string) []string { intermediate := []KeyValue{} file, err := os.Open(mapFileName) if err != nil { log.Fatalf("cannot open %v", mapFileName) } content, err := io.ReadAll(file) if err != nil { log.Fatalf("cannot read %v", mapFileName) } file.Close() kva := mapf(mapFileName, string(content)) intermediate = append(intermediate, kva...) intermediateFileNames := make([]string, reduceNum) intermediateFiles := make([]*os.File, reduceNum) for i := 0; i < reduceNum; i++ { oname := "mr" oname = oname + "_" + taskId + "_" + strconv.Itoa(i) ofile, _ := os.Create(oname) intermediateFiles[i] = ofile intermediateFileNames[i] = oname } for _, kv := range intermediate { //将数据写入到对应的文件中。为了方便reduce读取,所以选择以json格式写入 index := ihash(kv.Key) % reduceNum enc := json.NewEncoder(intermediateFiles[index]) enc.Encode(&kv) } return intermediateFileNames } func HandleReduceTask(reducef func(string, []string) string, reduceFilesName []string) string { intermediateFiles := make([]*os.File, len(reduceFilesName)) intermediate := []KeyValue{} for i := 0; i < len(reduceFilesName); i++ { intermediateFiles[i], _ = os.Open(reduceFilesName[i]) kv := KeyValue{} dec := json.NewDecoder(intermediateFiles[i]) for { if err := dec.Decode(&kv); err != nil { break } intermediate = append(intermediate, kv) } } sort.Sort(ByKey(intermediate)) oname := "mr-out-" index := reduceFilesName[0][strings.LastIndex(reduceFilesName[0], "_")+1:] oname = oname + index ofile, _ := os.Create(oname) // // call Reduce on each distinct key in intermediate[], // and print the result to mr-out-0. // i := 0 for i < len(intermediate) { j := i + 1 for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key { j++ } values := []string{} for k := i; k < j; k++ { values = append(values, intermediate[k].Value) } output := reducef(intermediate[i].Key, values) // this is the correct format for each line of Reduce output. fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output) i = j } return oname }
三、bug
代码的逻辑其实还是比较简单的,主要是设计几个结构体来彼此通信,有一个点卡了我一会,就是对于TaskType这个,最开始我只设定了Map、Reduce两种状态,后面测试出现问题,原因在于mrcoordinator每隔一秒钟调用Done()函数来判断整个任务是否完成,而Done是通过c.reduceFinishedCount == c.reduceNumber来判断的。
如果没有后面加入的Sleep状态,所有Reduce任务完成后,由于worker会不断向coordinator发送任务请求,coordinator的代码逻辑中没有对于所有Reduce任务完成后的处理,导致worker仍然再不停的进行处理空的Map任务,不断打印HandleMap中的log.Fatalf(“cannot open %v”, mapFileName)这一错误。
 微信
微信 支付宝
支付宝
