Lab 链接:https://pdos.csail.mit.edu/6.824/labs/lab-raft.html https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
Raft这个lab的难度相比较与前两个提高了很多,由于我之前接触过这个lab,所以上手还是很快的,lab3主要有4个子任务,我也会分任务进行记载。
Raft 是一种分布式一致性协议,旨在解决分布式系统中数据一致性和容错性的问题。为此,Raft 会首先在系统内自动选出一个 Leader 节点,并由这个 Leader 节点负责维护系统内所有节点上的操作日志的一致性。Leader 节点将负责接收用户的请求,将用户请求中携带的操作日志 replicate 到系统内的各个节点上,并告诉系统内各个节点将操作日志中的操作序列应用到各个节点中的状态机上。
更详细的细节会在后续实现当中说明。
3A Leader election
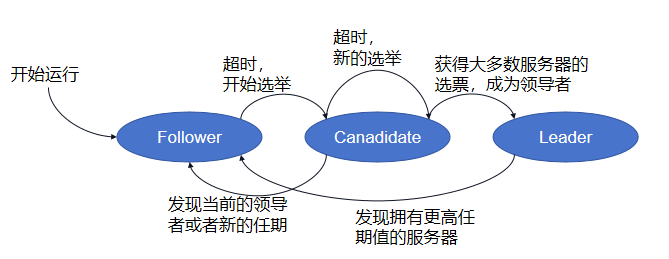
Lab 3A要求我们实现Leader选取。在Raft中,Server分为三种状态:Leader 、Follower 、 Candidate。初始情况下都为 Follower 。三种状态的转变流程如图所示:
我们需要做的就是借助rpc通信实现这个过程
对于具体的结构设计,raft论文已经给我们指出了,如下所示:
阅读论文的第5节,我们可以知道,Leader选取的过程如下:
初始情况下,所有节点均为Follower,当心跳检测超时时,Follower会转换为Candidate状态,并开始选举
每一个收到投票请求的Server,判断rpc中参数是否符合上图figure2的要求,如果符合,则投票,否则拒绝投票
如果Server得到了超过半数的投票,则Server成为Leader,并向其他Server发送心跳,保持Leader状态
若超时时间内无新的Leader产生, 再进行下一轮投票, 为了避免出现论文中所说的选举几轮都无Leader产生的情况, 应当给不同Server的投票超时设定随机值
当然,在实现过程中还有许多细节,下面在代码逻辑中详细给出
3A 代码逻辑
对于Raft结构体、RequestVote以及AppendEntrys的结构,我们参照Figure2实现即可,除此之外对于Raft结构体,我还添加了下列元素:
1 2 3 4 state int electionTimeout time.Duration timeStamp time.Time validVoteCount int
state即服务器状态;electionTimeout为选举超时时间,即为每个Server设定一个不同的重新发起选取Leader的超时时间;timeStamp为当前时间,以此与electionTimeout比较来确定是否超时;validVoteCount为当前有效投票数
Lab已告诉我们在ticker中检测是否需要发起选举我们利用time.Since()来实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (rf *Raft) ticker() { for rf.killed() == false { // Your code here (3A) // Check if a leader election should be started. // pause for a random amount of time between 50 and 350 // milliseconds. rf.mu.Lock() if rf.state != Leader && time.Since(rf.timeStamp) > rf.electionTimeout { go rf.election() } rf.mu.Unlock() ms := 50 + (rand.Int63() % 300) time.Sleep(time.Duration(ms) * time.Millisecond) } }
如果超时,就发起一个协程进行选举。在选举函数中,我们需要更新Server的自身状态,并且异步的向其他server发起投票请求,即RequetVote RPC。下面函数中的collectVote是对sendRequetVote的封装,以更简单的实现异步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (rf *Raft) election() { rf.mu.Lock() rf.state = Candidate rf.currentTerm++ // increment current term rf.votedFor = rf.me // vote for self rf.validVoteCount = 1 // count the vote for self rf.timeStamp = time.Now() // update timeStamp args := &RequestVoteArgs{ Term: rf.currentTerm, CandidateId: rf.me, LastLogIndex: len(rf.log) - 1, LastLogTerm: rf.log[len(rf.log)-1].Term, } rf.mu.Unlock() // send RequestVote RPCs to all other servers concurrently. for server, _ := range rf.peers { if server != rf.me { go rf.collectVote(server, args) } } }
collectVote发起投票请求,并且处理投票结果。collectVote调用sendRequestVote发送投票请求
如果RPC调用失败, 直接返回
如果server回复了更大的term, 表示当前这一轮的投票已经废弃, 按照回复更新term、自身角色和投票数据,返回false
如果发现当前投票已经结束了(即票数过半), 返回
否则按照投票结果对自身票数自增,自增后如果票数过半, 检查状态后转换自身角色为Leader,并开始发送心跳特别注意 ,在转化角色前必须先检测自己是否为Follower,因为collectVote也是与RPC心跳的handler并发的, 可能新的Leader已经产生, 并通过心跳改变了自己的role为Follower, 如果不检查的话, 将导致多个Leader的存在
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 func (rf *Raft) collectVote(server int, args *RequestVoteArgs) { reply := RequestVoteReply{} ok := rf.sendRequestVote(server, args, &reply) if !ok { return } rf.mu.Lock() defer rf.mu.Unlock() if args.Term != rf.currentTerm { return } if reply.Term > rf.currentTerm { rf.currentTerm = reply.Term rf.votedFor = -1 rf.state = Follower // convert to follower if term is greater than current term. } if !reply.VoteGranted { return } if rf.validVoteCount > len(rf.peers)/2 { // majority vote received, become leader. return } rf.validVoteCount++ if rf.validVoteCount > len(rf.peers)/2 { // majority vote received, become leader. if rf.state == Follower { return } rf.state = Leader // become leader. go rf.sendHeartbeat() // start sending heartbeat. } }
投票的接收方即RequestVote函数则严格按照Figure 2进行设计:
如果args.Term < rf.currentTerm, 直接拒绝投票, 并告知更新的投票
如果args.Term > rf.currentTerm, 更新rf.votedFor = -1, 之前轮次的投票作废 ,令 rf.currentTerm = args.Term ,解决孤立节点Term过大的情况
如果满足下面两个情况之一, 投票, 然后更新currentTerm, votedFor,role, timeStamp
args.LastLogTerm > rf.log[len(rf.log)-1].Term
args.LastLogTerm == rf.log[len(rf.log)-1].Term && args.LastLogIndex >= len(rf.log)-1, 并且未投票或者投票对象是自己
其他情况不投票
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 // example RequestVote RPC handler. func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) { // Your code here (3A, 3B). rf.mu.Lock() defer rf.mu.Unlock() if args.Term < rf.currentTerm { reply.Term = rf.currentTerm reply.VoteGranted = false return } if args.Term > rf.currentTerm { // new term rf.votedFor = -1 rf.currentTerm = args.Term // solve the problem about Orphaned node rf.state = Follower } if rf.votedFor == -1 || rf.votedFor == args.CandidateId { if args.LastLogTerm > rf.log[len(rf.log)-1].Term || (args.LastLogTerm == rf.log[len(rf.log)-1].Term && args.LastLogIndex >= len(rf.log)-1) { rf.votedFor = args.CandidateId rf.currentTerm = args.Term rf.state = Follower rf.timeStamp = time.Now() reply.Term = rf.currentTerm reply.VoteGranted = true return } } reply.Term = rf.currentTerm reply.VoteGranted = false }
leader产生后就需要立即发送心跳rpc,不断调用sendAppendEntries函数,发送空的Entries
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 func (rf *Raft) sendHeartbeat() { for rf.killed() == false { rf.mu.Lock() if rf.state != Leader { // stop sending heartbeat if not leader. rf.mu.Unlock() return } rf.mu.Unlock() for server := range rf.peers { args := &AppendEntriesArgs{ Term: rf.currentTerm, LeaderId: rf.me, PrevLogIndex: 0, PrevLogTerm: 0, Entries: nil, LeaderCommit: rf.commitIndex, } if server != rf.me { go rf.handleHeartbeat(server, args) } } time.Sleep(time.Duration(heartBeatTimeout)) } } func (rf *Raft) handleHeartbeat(server int, args *AppendEntriesArgs) { reply := &AppendEntriesReply{} ok := rf.sendAppendEntries(server, args, reply) if !ok { return } rf.mu.Lock() defer rf.mu.Unlock() if args.Term != rf.currentTerm { return } if reply.Term > rf.currentTerm { rf.currentTerm = reply.Term // update currentTerm. rf.votedFor = -1 rf.state = Follower // become follower. } }
对于AppendEntries函数,同样严格按照Figure 2实现即可
如果term < currentTerm表示这是一个旧leader的消息, 告知其更新的term并返回false
如果args.Term > currentTerm, 更新currentTerm, 并转换为follower状态,同时要记得令rf.votedFor = -1,终止其他不应该继续的投票
如果自己的日志中prevLogIndex处不存在有效的日志, 或者与prevLogTerm不匹配, 返回false
如果现存的日志与请求的信息冲突, 删除冲突的日志(这一部分不涉及)
添加日志(这一部分不涉及)
如果leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
3B Log
3B 主要是实现日志复制以及其引出的选举限制
日志复制核心是通过AppendEntries RPC中的PrevLogIndex、PrevLogTerm来校验Follower的日志是否与Leader一致,如果不一致,则需要通过AppenEntriesRPc来达到一致。前两者的值由nextIndex决定。具体细节边讲代码边讲
心跳Rpc和正常的AppendEntries的区别仅在于是否携带Logs,因此我们在2A的代码的基础上改变心跳Rpc的代码即可
3B代码逻辑
在sendHeartbeat()函数中,我们需要为每个server单独构建AppendEntriesArgs,有以下要点:
PrevLogIndex = rf.nextIndex[i] - 1 即follower最后一个有效日志
PrevLogTerm = rf.log[rf.nextIndex[i]-1].Term 即follower最后一个有效日志的任期
如果len(rf.log)-1 >= rf.nextIndex[i],则表明有新的log需要发送,需要携带Logs,否则就发送一个空log作为心跳rpc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for server := range rf.peers { if server == rf.me { // skip self continue } args := &AppendEntriesArgs{ Term: rf.currentTerm, LeaderId: rf.me, PrevLogIndex: rf.nextIndex[server] - 1, PrevLogTerm: rf.log[rf.nextIndex[server]-1].Term, LeaderCommit: rf.commitIndex, } if len(rf.log)-1 >= rf.nextIndex[server] { // send log entries. args.Entries = rf.log[rf.nextIndex[server]:] // send remaining logs. } else { // send heartbeat. args.Entries = make([]LogEntry, 0) // send empty log entries. } go rf.handleAppendEntries(server, args) }
在对AppendEntries返回的信息的处理中,handleAppendEntries(server, args),在success时,我们需要更新rf.nextIndex[server]和rf.matchIndex[server],判断是否可以commit,更改commitIndex
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 if reply.Success { rf.matchIndex[server] = args.PrevLogIndex + len(args.Entries) // update matchIndex. rf.nextIndex[server] = rf.matchIndex[server] + 1 // update nextIndex. for N := len(rf.log) - 1; N > rf.commitIndex; N-- { // update commitIndex count := 1 for peer := range rf.peers { if peer != rf.me && rf.matchIndex[peer] >= N && rf.log[N].Term == rf.currentTerm { // check if majority of matchIndex is greater than or equal to N. count++ // count the number of servers that have log entry at index N. } } if count > len(rf.peers)/2 { // if majority of servers have log entry at index N. rf.commitIndex = N // update commitIndex. break // break the loop. } } rf.condApply.Signal() return }
在handleAppendEntries(server, args)还有一个要点,在follower的日志和leader的不同时,需要leader调整nextIndex重试,这里使用6.5840有提到的快速回滚的方法,在AppendEntriesReply中添加三个元素
1 2 3 XTerm: Follower中与Leader冲突的Log对应的Term, 如果Follower在对应位置没有Log将其设置为-1 XIndex: Follower中,对应Term为XTerm的第一条Log条目的索引 XLen: 空白的Log槽位数, 如果Follower在对应位置没有Log,那么XTerm设置为-1,在实际代码中,我们将其设定为Fowller的log长度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if reply.Term == rf.currentTerm && rf.state == Leader { // if the follower's log is inconsistent with the leader's log. // quick rollback if reply.XTerm == -1 { rf.nextIndex[server] = reply.XLen return } index := rf.nextIndex[server] - 1 for index > 0 && rf.log[index].Term > reply.XTerm { index-- } if rf.log[index].Term == reply.XTerm { rf.nextIndex[server] = index + 1 // update nextIndex. } else { rf.nextIndex[server] = reply.XIndex } return }
在AppendEntries()中,Follower收到回复后, 按如下规则做出反应:
如果XTerm != -1, 表示PrevLogIndex这个位置发生了冲突, Follower检查自身是否有Term为XTerm的日志项
如果有, 则将nextIndex[i]设置为自己Term为XTerm的最后一个日志项的下一位, 这样的情况出现在Follower有着更多旧Term的日志项(Leader也有这样Term的日志项), 这种回退会一次性覆盖掉多余的旧Term的日志项
如果没有, 则将nextIndex[i]设置为XIndex, 这样的情况出现在Follower有着Leader所没有的Term的旧日志项, 这种回退会一次性覆盖掉没有出现在Leader中的Term的日志项
如果XTerm == -1, 表示Follower中的日志不存在PrevLogIndex处的日志项, 这样的情况出现在Follower的log数组长度更短的情况下, 此时将nextIndex[i]减去XLen
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if args.PrevLogIndex >= len(rf.log) { // Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3) reply.XTerm = -1 reply.XLen = len(rf.log) reply.Term = rf.currentTerm reply.Success = false return } else if rf.log[args.PrevLogIndex].Term != args.PrevLogTerm { reply.XTerm = rf.log[args.PrevLogIndex].Term i := args.PrevLogIndex for rf.log[i].Term == reply.XTerm { i -= 1 } reply.XIndex = i + 1 reply.Term = rf.currentTerm reply.Success = false return }
之后Follower需要依据PrevLogIndex删除非法的logs,并添加新的log
1 2 3 4 if len(args.Entries) != 0 && len(rf.log) > args.PrevLogIndex+1 { rf.log = rf.log[:args.PrevLogIndex+1] } rf.log = append(rf.log, args.Entries...)
最后实现一个将commit应用到状态机的协程,可以使用条件变量或者time.Sleep实现,lab中hints提示了不能不断执行,逻辑还是比较简单的,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func (rf *Raft) applyMsgToStatemachine() { for rf.killed() == false { rf.mu.Lock() for rf.commitIndex <= rf.lastApplied { rf.condApply.Wait() } for rf.commitIndex > rf.lastApplied { rf.lastApplied++ msg := &ApplyMsg{ CommandValid: true, Command: rf.log[rf.lastApplied].Command, CommandIndex: rf.lastApplied, } rf.applych <- *msg } rf.mu.Unlock() // time.Sleep(10 * time.Millisecond) // sleep for 10 milliseconds. } }
易错点 :每次选出新的leader后需要重新初始化nextIndex[]和matchIndex[]:
1 2 3 4 5 6 7 8 9 10 11 if rf.validVoteCount > len(rf.peers)/2 { // majority vote received, become leader. if rf.state == Follower { return } rf.state = Leader // become leader. for i := 0; i < len(rf.nextIndex); i++ { rf.nextIndex[i] = len(rf.log) rf.matchIndex[i] = 0 } go rf.sendHeartbeat() // start sending heartbeat. }
在实现了快速回滚的情况下,测试的结果时间还是比较长,潜在的问题可能是在更新commitIndex处使用了一个循环,导致时间复杂度过高,目前还没想到好的优化方案,后面再说
3C Persistence
3C的任务是实现可持久化,如果基于 Raft 的服务器重新启动,它应该从中断处恢复服务。这要求 Raft 保持在重启后仍然存在的持久状态。
论文中提到需要我们持久化的数据只有三个:votedFor、currentTerm、Log。
votedFor:
votedFor记录了一个节点在某个Term内的投票记录, 因此如果不将这个数据持久化, 可能会导致如下情况:
在一个Term内某个节点向某个Candidate投票, 随后故障。故障重启后, 又收到了另一个RequestVote RPC, 由于其没有将votedFor持久化, 因此其不知道自己已经投过票, 结果是再次投票, 这将导致同一个Term可能出现2个Leader
currentTerm:
currentTerm的作用也是实现一个任期内最多只有一个Leader, 因为如果一个几点重启后不知道现在的Term时多少, 其无法再进行投票时将currentTerm递增到正确的值, 也可能导致有多个Leader在同一个Term中出现
Log:
而其他的数据如commitIndex、lastApplied、nextIndex、matchIndex都可以通过rpc信息重建
3C代码逻辑
完善代码框架中的persist()和readPersist(),照着注释写即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (rf *Raft) persist() { w := new(bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(rf.currentTerm) e.Encode(rf.votedFor) e.Encode(rf.log) raftstate := w.Bytes() rf.persister.Save(raftstate, nil) } // restore previously persisted state. func (rf *Raft) readPersist(data []byte) { if data == nil || len(data) < 1 { // bootstrap without any state? return } r := bytes.NewBuffer(data) d := labgob.NewDecoder(r) var currentTerm int var votedFor int var log []LogEntry if d.Decode(¤tTerm) != nil || d.Decode(&votedFor) != nil || d.Decode(&log) != nil { DPrintf("readPersist failed\n") } else { rf.currentTerm = currentTerm rf.votedFor = votedFor rf.log = log } }
在其他函数中,只要修改了currentTerm、votedFor、log,我们就进行持久化。在make函数中,由于崩溃恢复时readPersist修改了log,我们需要在执行readPersist后对nextIndex进行初始化:
1 2 3 4 5 6 7 8 9 10 func Make ... { ... // initialize from state persisted before a crash rf.readPersist(persister.ReadRaftState()) for i := 0; i < len(rf.nextIndex); i++ { rf.nextIndex[i] = len(rf.log) } ... }
测试了很多次,结果和lab相差不大,是否就可以不管2B的结果了?
3D Log Compaction
3D的任务是实现日志压缩,即Snapshot快照的实现。快照是Raft要求上层的应用程序做的, 因为Raft本身并不理解应用程序的状态和各种命令;Raft需要选取一个Log作为快照的分界点, 在这个分界点要求应用程序做快照, 并删除这个分界点之前的Log;在持久化快照的同时也持久化这个分界点之后的Log。
以一个K/V数据库为例, Log就是Put或者Get, 当这个应用运行了相当长的时间后, 其积累的Log将变得很长, 但K/V数据库实际上键值对并不多, 因为Log包含了大量的对同一个键的赋值或取值操作。因此, 应当设计一个阈值,例如1M, 将应用程序的状态做一个快照,然后丢弃这个快照之前的Log。
3D代码设计
参考原论文中的figure13,实现snapshot的代码。首先我们需要在Raft结构体中加入下面几个成员,保存snapshot的信息:
1 2 3 4 5 6 type Raft struct { ... snapShot []byte // snapshot of the state machine for fast recovery lastIncludedIndex int // index of the last entry in the snapshot for fast recovery lastIncludedTerm int // term of the last entry in the snapshot for fast recovery }
比较关键的一个问题,每次对log进行截断时,commitIndex和nextIndex等索引该如何更新呢?
1 2 realIndex = globalIndex - rf.lastIncludedIndex globalIndex = rf.lastIncludedIndex + realIndex
访问rf.log我们使用realIndex,其他情况均使用globalIndex。这样就可以很好的解决对于索引的操作,并且注意,我的代码中索引都是从1开始的,0是占位符
Snapshot()函数负责在接受到应用层的快照请求后,进行快照的生成,并更新Raft结构体中的snapshot和lastIncludedIndex等成员。
当index > commitIndex 或者 lastIncludedIndex 时需要拒绝该请求,否则就可以保存snapshot并更改相应状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (rf *Raft) Snapshot(index int, snapshot []byte) { // Your code here (3D). rf.mu.Lock() defer rf.mu.Unlock() if rf.commitIndex < index || index <= rf.lastIncludedIndex { return } rf.snapShot = snapshot rf.lastIncludedTerm = rf.log[rf.RealLogIndex(index)].Term rf.log = rf.log[rf.RealLogIndex(index):] // log[0] store log[index] rf.lastIncludedIndex = index if rf.lastApplied < index { rf.lastApplied = index } rf.persist() }
然后需要更改代码中涉及索引的部分,以及对于3C中的可持久化的部分也需要更改,具体就不赘述了
特别在make初始化时,我们需要读取快照和可持久化,因此我们也需要更改nextIndex,此时就需要注意其索引
1 2 3 4 5 6 7 // initialize from state persisted before a crash rf.readSnapshot(persister.ReadSnapshot()) rf.readPersist(persister.ReadRaftState()) for i := 0; i < len(rf.nextIndex); i++ { rf.nextIndex[i] = rf.GlobalLogIdx(len(rf.log)) // index start by 1 }
3D部分的重点是InstallSnapshot RPC的实现
假设有一个Follower的日志数组长度很短, 短于Leader做出快照的分界点, 那么这中间缺失的Log将无法通过心跳AppendEntries RPC发给Follower, 因此这个确实的Log将永久无法被补上。因此我们需要实现一个InstallSnapshot RPC,用于在Leader和Follower之间传输快照,以补全缺失的Log。Leader稍后再通过AppendEntries RPC发送快照后的Log。
参考原论文Figure 13的设计:
1 2 3 4 5 6 7 8 9 10 11 12 type InstallSnapshotArgs struct { Term int // leader’s term LeaderId int // so follower can redirect clients LastIncludedIndex int // snapshot replaces log[index:] LastIncludedTerm int // term of lastIncludedIndex Data []byte // raw bytes of the snapshot chunk LastIncludedCmd interface{} // inorder to occupy position at 0 } type InstallSnapshotReply struct { Term int // currentTerm, for leader to update itself }
LastIncludedCmd用于对0索引日志的占位使用,截断后的日志,使用LastIncludedIndex位置的日志项对0号日志进行占位
在sendHeartbeat()心跳函数中,如果args.PrevLogIndex < rf.lastIncludedIndex,说明Follower的日志过短,则发送InstallSnapshot RPC
在handleAppendEntries()处理RPC回复的函数中,如果发现已经回退到lastIncludedIndex还不能满足要求, 就需要发送InstallSnapshot RPC
发送InstallSnapshot RPC的handleInstallSnapshot函数实现如下:注意发送Rpc时不要持有锁,并且发送成功后需要将nextIndex设置为GlobalLogIdx(1), 因为0索引处是占位, 其余的部分已经不需要再发送了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func (rf *Raft) handleInstallSnapshot(server int) { reply := &InstallSnapshotReply{} rf.mu.Lock() if rf.state != Leader { rf.mu.Unlock() return } args := &InstallSnapshotArgs{ Term: rf.currentTerm, LeaderId: rf.me, LastIncludedIndex: rf.lastIncludedIndex, LastIncludedTerm: rf.lastIncludedTerm, Data: rf.snapShot, LastIncludedCmd: rf.log[0].Command, } rf.mu.Unlock() ok := rf.sendInstallSnapshot(server, args, reply) if !ok { return } rf.mu.Lock() defer rf.mu.Unlock() if reply.Term > rf.currentTerm { rf.state = Follower rf.currentTerm = reply.Term rf.votedFor = -1 rf.timeStamp = time.Now() rf.persist() return } rf.nextIndex[server] = rf.GlobalLogIdx(1) }
而对于InstallSnapshot Rpc的响应,特别需要注意的是要检查lastApplied和commitIndex 是否小于LastIncludedIndex, 如果是, 更新为LastIncludedIndex;同时要记得更新定时器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) { rf.mu.Lock() defer func() { rf.timeStamp = time.Now() rf.mu.Unlock() }() // Reply immediately if term < currentTerm if args.Term < rf.currentTerm { reply.Term = rf.currentTerm return } if args.Term > rf.currentTerm { rf.currentTerm = args.Term rf.votedFor = -1 } rf.state = Follower // If existing log entry has same index and term as snapshot’s last included entry, retain log entries following it and reply hasEntry := false realIdx := 0 for ; realIdx < len(rf.log); realIdx++ { if rf.GlobalLogIdx(realIdx) == args.LastIncludedIndex && rf.log[realIdx].Term == args.LastIncludedTerm { hasEntry = true break } } msg := &ApplyMsg{ SnapshotValid: true, Snapshot: args.Data, SnapshotTerm: args.LastIncludedTerm, SnapshotIndex: args.LastIncludedIndex, } if hasEntry { rf.log = rf.log[realIdx:] } else { rf.log = make([]LogEntry, 0) rf.log = append(rf.log, LogEntry{Term: rf.lastIncludedTerm, Command: args.LastIncludedCmd}) } // Discard the entire log // Reset state machine using snapshot contents (and load snapshot’s cluster configuration) rf.snapShot = args.Data rf.lastIncludedIndex = args.LastIncludedIndex rf.lastIncludedTerm = args.LastIncludedTerm if rf.commitIndex < args.LastIncludedIndex { rf.commitIndex = args.LastIncludedIndex } if rf.lastApplied < args.LastIncludedIndex { rf.lastApplied = args.LastIncludedIndex } reply.Term = rf.currentTerm rf.applych <- *msg rf.persist() }
在测试时,由于有许多地方需要更改,所以要不断的dubug,最好就是写好日志输出信息慢慢找,详细的就不赘述了。有一点就是在apply msg到状态机时,rf.applyCh <- *msg不能够加锁,否则由于该通道长时间阻塞而产生死锁现象。
1 2 3 4 for i := 0; i < len(rf.nextIndex); i++ { rf.nextIndex[i] = rf.VirtualLogIdx(len(rf.log)) rf.matchIndex[i] = rf.lastIncludedIndex }
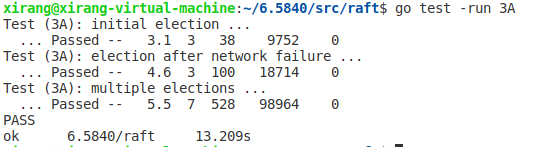
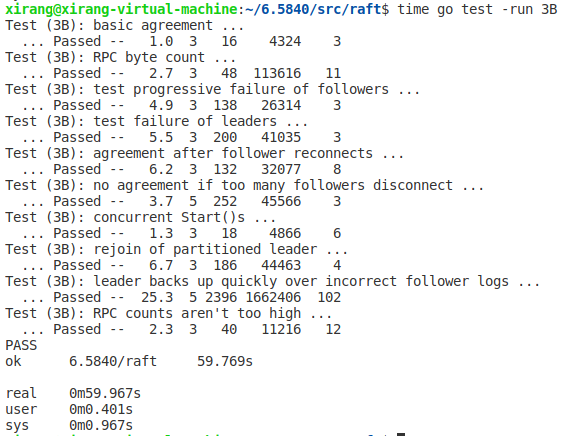
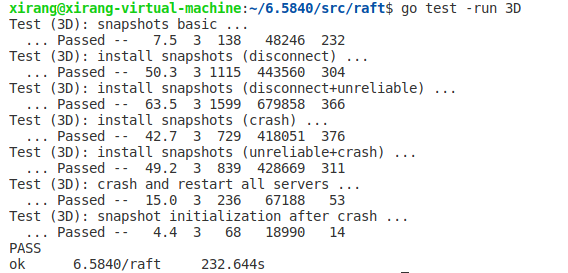
最后的测试结果如下,大量测试后显示效果比lab中的还有好一些



 微信
微信 支付宝
支付宝
