func (ck *Clerk) PutAppend(key string, value string, op string) { // You will have to modify this function. args := &PutAppendArgs{Key: key, Value: value, Op: op, Seq: ck.GetSeq(), Identifier: ck.identifier}
for { reply := &PutAppendReply{} ok := ck.servers[ck.leaderId].Call("KVServer.PutAppend", args, reply) if !ok || reply.Err == ErrNotLeader || reply.Err == ErrLeaderOutDated { ck.leaderId += 1 ck.leaderId %= len(ck.servers) continue }
switch reply.Err { case ErrChanClose: continue case ErrHandleOpTimeOut: continue } return } }
func (kv *KVServer) ApplyHandler() { for !kv.killed() { log := <-kv.applyCh if log.CommandValid { op := log.Command.(Op) kv.mu.Lock()
needApply := false var res LastRpc if lastrpc, ok := kv.lastRpc[op.ClientId]; ok { if lastrpc.LastRpcSeq == op.RpcSeq { res = lastrpc } else if lastrpc.LastRpcSeq < op.RpcSeq { needApply = true } } else { needApply = true }
if needApply { res = kv.KvMapExecute(&op) res.ApplyTerm = log.SnapshotTerm kv.lastRpc[op.ClientId] = res }
ch, ok := kv.waiCh[log.CommandIndex] if !ok { kv.mu.Unlock() continue } kv.mu.Unlock() res.ApplyTerm = log.SnapshotTerm ch <- res } } }
func (kv *KVServer) KvMapExecute(op *Op) (res LastRpc) { res.LastRpcSeq = op.RpcSeq switch op.OpType { case OpGet: value, ok := kv.kvMap[op.Key] if ok { res.Value = value return } else { res.Err = ErrNoKey res.Value = "" return } case OpPut: kv.kvMap[op.Key] = op.Value return case OpAppend: value, ok := kv.kvMap[op.Key] if ok { kv.kvMap[op.Key] = value + op.Value return } else { kv.kvMap[op.Key] = op.Value return } } return }
func (kv *KVServer) ApplyHandler() { for !kv.killed() { log := <-kv.applyCh if log.CommandValid { ... } else if log.SnapshotValid { kv.mu.Lock() if log.SnapshotIndex >= kv.lastApplied { kv.ReadSnapShot(log.Snapshot) kv.lastApplied = log.SnapshotIndex } kv.mu.Unlock() } } }
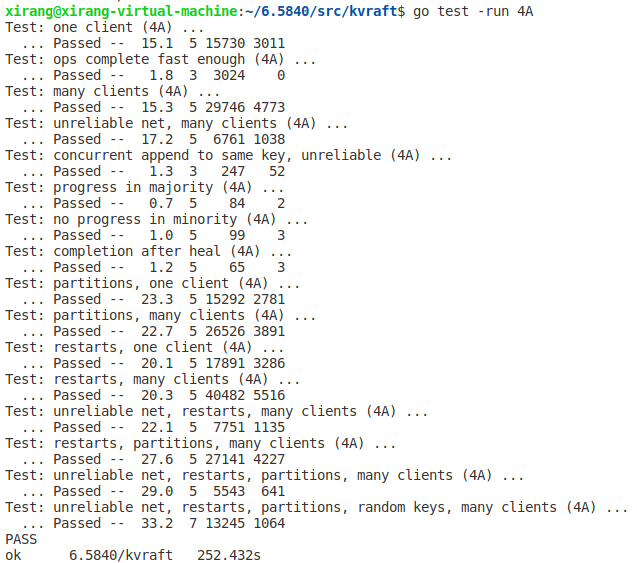
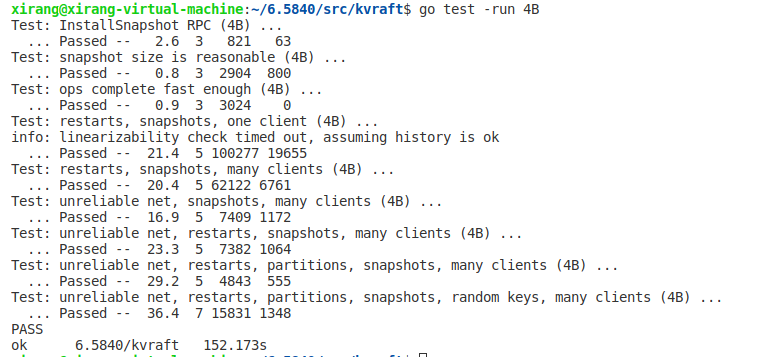
K/V server部分的代码就完成了,但是不出意外就报错了,在测试时出现了logs were not trimmed的错误,在检测了没有死锁和持锁接发通道消息等问题后,发现应该是raft层无法承受高并发而导致clerk无限重发Rpc,因此我们要减少raft发送Rpc的数量并且让clerk在失败时等待一会

 微信
微信 支付宝
支付宝
