CMU15-445 bustub Project3:Query Execution
写在前面
参考资料:
- https://zhuanlan.zhihu.com/p/587566135
- https://www.bilibili.com/video/BV1bQ4y1Y7iT
知乎那个博主写的非常好,对我的启发很大,感激~
Project3:Query Execution 主要是实现查询过程中的一系列算子,就难度,个人感觉是不如lab2的B+tree的,主要是需要阅读源码,并且要对Bustub的体系结构以及查询引擎的原理有一定的理解。
主要任务如下:
- Task1:Access Method Executors. 包含 SeqScan、Insert、Delete、IndexScan 四个算子。
- Task2:Aggregation and Join Executors. 包含 Aggregation、NestedLoopJoin、NestedIndexJoin 三个算子。
- Task3:Sort + Limit Executors and Top-N Optimization. 包含 Sort、Limit、TopN 三个算子,以及实现将 Sort + Limit 优化为 TopN 算子。
- Leaderboard Task:为 Optimizer 实现新的优化规则,目前我仅做了hash join,其他优化如Join Reordering、Filter Push Down、Column Pruning等有时间了再完成
前置知识
下图是官网给出的BusTub的整体架构,在开始之前我会阐述一下一条sql语句在BusTub中的执行过程。(部分内容参考上面的知乎链接)
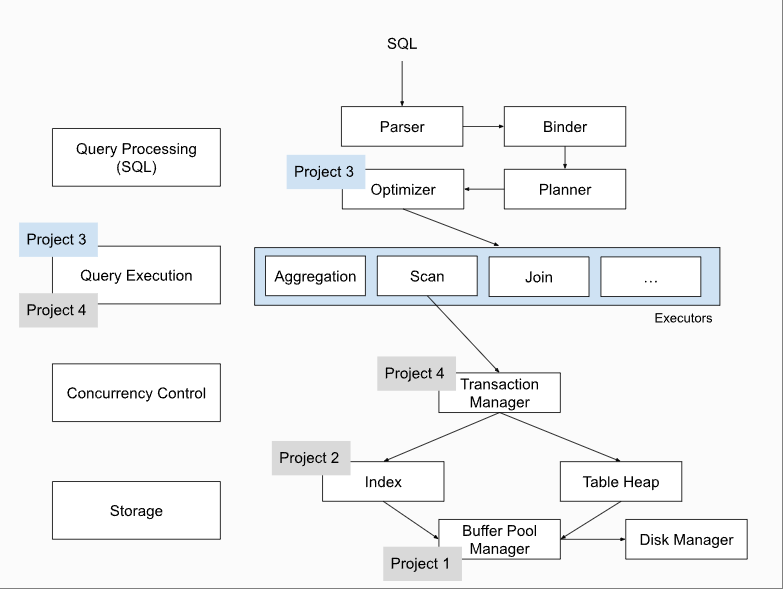
Parse
一条 sql 语句,首先经过 Parser 生成一棵抽象语法树 AST。Bustub 中采用了 libpg_query 库将 sql 语句 parse 为 AST。
Binder
Binder 的工作是将AST转变为Bustub AST,即将AST上的关键词绑定到数据库实体(c++类)上。
例如有这样一条 sql:
1 | SELECT colA FROM table1; |
其中 SELECT 和 FROM 是关键字,colA 和 table1 是标识符。Binder 遍历 AST,将这些词语绑定到相应的实体上。实体是 Bustub 可以理解的各种 c++ 类。绑定完成后,得到的结果是一棵 Bustub 可以直接理解的树。把它叫做 Bustub AST。
Planner
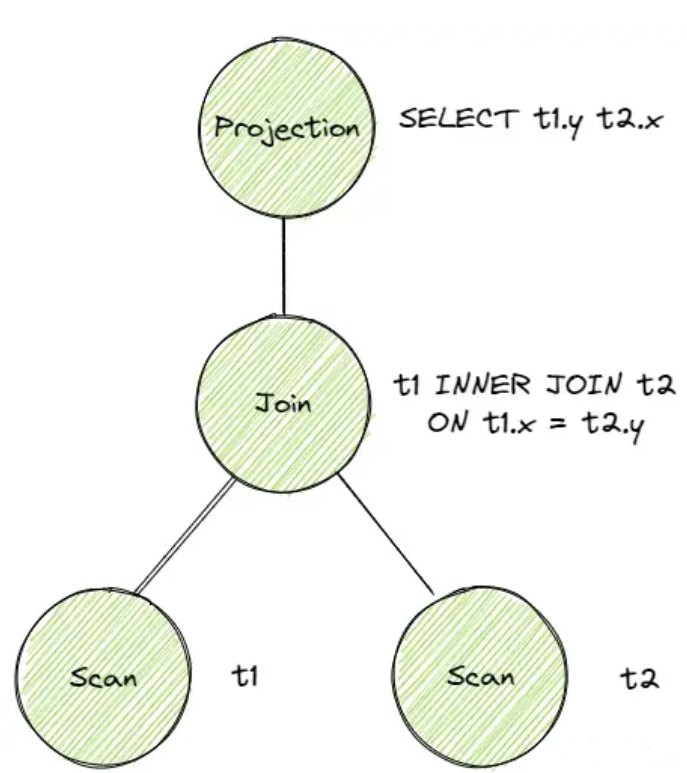
Planner对 Bustub AST 进行遍历生成初步的查询计划。查询计划也是一棵树的形式。同时查询计划规定了数据的流向。数据从树叶流向树根,自底向上地流动,在根节点输出结果。
例如这条 sql:
1 | SELECT t1.y, t2.x FROM t1 INNER JOIN t2 ON t1.x = t2.y; |
生成的原始查询计划如下图(摘至上面提到的博客,下文类似的图均来自此博客):
Optimizer
Optimizer 顾名思义,就是对查询计划进行修改优化,生成最终的查询计划。Optimizer 主要有两种实现方式:
- Rule-based. Optimizer 遍历初步查询计划,根据已经定义好的一系列规则,对 PlanNode 进行一系列的修改、聚合等操作。例如我们在 Task 3 中将要实现的,将 Limit + Sort 合并为 TopN。这种 Optimizer 不需要知道数据的具体内容,仅是根据预先定义好的规则修改 Plan Node。
- Cost-based. 这种 Optimizer 首先需要读取数据,利用统计学模型来预测不同形式但结果等价的查询计划的 cost。最终选出 cost 最小的查询计划作为最终的查询计划。
另外值得一提的是,一般来说,Planner 生成的是 Logical Plan Node,代表抽象的 Plan。Optimizer 则生成 Physical Plan Node,代表具体执行的 Plan。一个比较典型的例子是 Join。在 Planner 生成的查询计划中,Join 就是 Join。在 Optimizer 生成的查询计划中,Join 会被优化成具体的 HashJoin 或 NestedIndexJoin 等等。在 Bustub 中,并不区分 Logical Plan Node 和 Physical Plan Node。Planner 会直接生成 Physical Plan Node。
Executor
在拿到 Optimizer 生成的具体的查询计划后,就可以生成真正执行查询计划的一系列算子了。算子也是我们在 Project 3 中需要实现的主要内容。生成算子的步骤很简单,遍历查询计划树,将树上的 PlanNode 替换成对应的 Executor。算子的执行模型也大致分为三种:
- Iterator Model,或 Pipeline Model,或火山模型。每个算子都有 Init() 和 Next() 两个方法。Init() 对算子进行初始化工作。Next() 则是向下层算子请求下一条数据。当 Next() 返回 false 时,则代表下层算子已经没有剩余数据,迭代结束。可以看到,火山模型一次调用请求一条数据,占用内存较小,但函数调用开销大,特别是虚函数调用造成 cache miss 等问题。
- Materialization Model. 所有算子立即计算出所有结果并返回。和 Iterator Model 相反。这种模型的弊端显而易见,当数据量较大时,内存占用很高。但减少了函数调用的开销。比较适合查询数据量较小的 OLTP workloads。
- Vectorization Model. 对上面两种模型的中和,一次调用返回一批数据。利于 SIMD 加速。目前比较先进的 OLAP 数据库都采用这种模型。
Bustub 采用的是 Iterator Model。
此外,算子的执行方向也有两种:
- Top-to-Bottom. 从根节点算子开始,不断地 pull 下层算子的数据。
- Bottom-to-Top. 从叶子节点算子开始,向上层算子 push 自己的数据。
Bustub 采用 Top-to-Bottom。
在根节点算子处,就得到了我们想要查询的数据,一条 sql 语句完成了它的使命。
好了写到这里就可以开始做lab了,但是很快发现自己还是一头雾水,不知从哪里开始。在指导书中,有提示我们使用TableIterator和Catalog,这两个是什么呢?
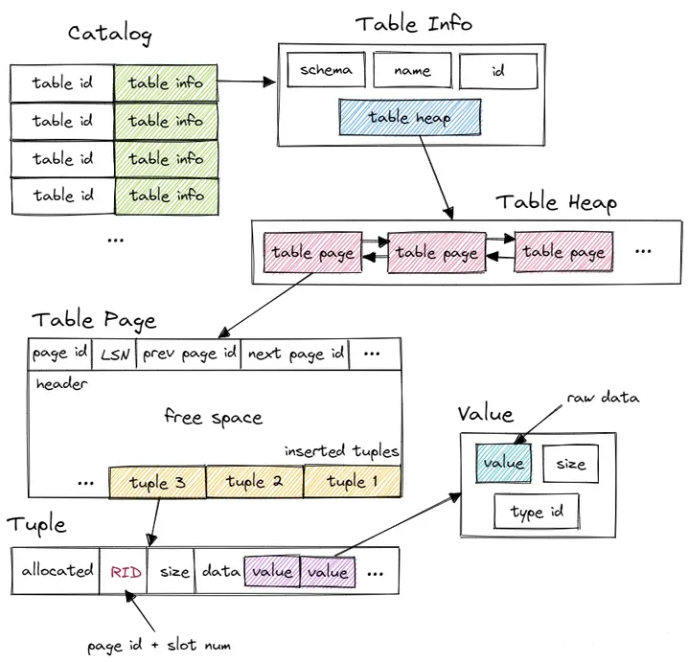
TableIterator其实是访问table heap的工具,而table heap是管理 table 数据的结构,可以理解为,物理内存由 Table Page 来决定,而逻辑结构则由 Table Heap 来决定。
Catalog:
1 | The Catalog is a non-persistent catalog that is designed for use by executors within the DBMS execution engine. It handles table creation, table lookup, index creation, and index lookup |
数据库并非是通过直接访问数据页来完成数据的增删查改,而是通过维护一个内部目录,来 traces 数据库中的元数据,在本项目中,同样需要通过与 System Catalog 的交互,以查询有关表、索引以及架构的信息。Catalog 维护了几张 hashmap,保存了 table id 和 table name 到 table info 的映射关系。table id 由 Catalog 在新建 table 时自动分配,table name 则由用户指定。这里的 table info 包含了一张 table 的 metadata,有 schema、name、id 和指向 table heap 的指针。系统的其他部分想要访问一张 table 时,先使用 name 或 id 从 Catalog 得到 table info,再访问 table info 中的 table heap。
查看task1我们需要完成的SeqScanExecutor类,可以看到引入了AbstractExecutor,ExecutorContext,SeqScanPlanNode,Tuple,Schema,大概的功能如下:
AbstractExecutor:火山式元组迭代器模型的实现,也是其余 Executor 的基类
ExecutorContext:存储了一个 Executor 的过程中所有必要的内容,包括 Transaction、Catalog、Buffer Pool Manager、Log Manager、Lock Manager、Transaction Manager对象和获取对象的接口。
SeqScanPlanNode:继承自 AbstractPlanNode,表示执行计划结点类型,每个节点会接收子节点的输出元组作为输入,且顺序相当重要。接口则主要涉及到执行计划的输出、获取子节点等。
Tuple:对应数据表中的一行数据。每个 tuple 都由 RID 唯一标识。RID 由 page id + slot num 构成。tuple 由 value 组成,value 的个数和类型由 table info 中的 schema 指定。
Schema:类如其名,主要接口多是关于获取表中的列的相关信息
最后,用上面提到的博客中的一张图结尾,很好的画出了table的结构,也揭示了我们应该怎么解决task:
Task1:Access Method Executors
SeqScan
引入TableIterator和TableInfo,在next中对TableIterator叠加即可
1 | TableIterator table_iterator_; |
TableIterator和TableInfo的获取我们都需要通过上文提到的ExecutorContext中的Catalog来得到:
1 | this->table_info_ = this->exec_ctx_->GetCatalog()->GetTable(plan_->table_oid_); |
Insert
利用api将tuple追加至table尾部:
1 | bool inserted = table_info_->table_->InsertTuple(insert_tuple, rid, exec_ctx_->GetTransaction()); |
同时要注意更新与 table 相关的所有 index。index 与 table 类似,同样由 Catalog 管理。需要注意的是,由于可以对不同的字段建立 index,一个 table 可能对应多个 index,所有的 index 都需要更新。
1 | if (inserted) { |
Next() 返回一个包含一个 integer value 的 tuple,表示 table 中有多少行受到了影响。
Delete
只需将insert中的相应api更改一下即可,Delete 时,并不是直接删除,而是将 tuple 标记为删除状态,也就是逻辑删除。(在事务提交后,再进行物理删除,Project 3 中无需实现)
IndexScan
利用Project 2 中实现的 B+Tree Index Iterator来查找,本项目中执行计划的索引对象始终为BPlusTreeIndexForOneIntegerColumn,可以安全地将其转化并存储在执行器对象中,可以从索引对象BPlusTreeIndexForOneIntegerColumn构造索引迭代器,扫描所有键和元组 ID,从表堆中查找元组,并按索引键的顺序发出所有元组作为执行器的输出。
1 | IndexScanExecutor::IndexScanExecutor(ExecutorContext *exec_ctx, const IndexScanPlanNode *plan) |
Next()中仅需访问iter_即可,但是要注意索引中保存的是RID,还需要利用 RID 去 table 查询对应的 tuple。
1 | *rid = (*iter_).second; |
Task 2 Aggregation & Join Executors
Aggregation
聚合的作用在于将一组值按照给定的结果进行合并。AggregationPlanNode有以下几类:
- GROUP BY(分组)
- COUNT/COUNT(*)、MIN、MAX(规则)
指导书中有以下提示:
1 | AggregationExecutor 不需要考虑处理 “HAVING” 过滤条件。原本 HAVING 的作用是对分组后的结果进行条件筛选,也可以用于在聚合计算后对聚合结果进行条件筛选。而在本实验中,planner 会将 having 处理成为 FilterPlanNode。因此,聚合执行器只需要对每组输入执行聚合,也就只有一个子节点(见执行计划输出结果,为MockScan) => 原本 “HAVING” 关键字也有聚合效果,但是本实验把它当作了 Filter 算子,因此 Aggregate 算子只需要考虑把“扫描”得到的结果做聚合即可。 |
同时注意到Aggregation 是 pipeline breaker,意思是在整个查询计划的执行过程(即Pipeline)中,其他的算子,例如SeqSacn,一步一步往下执行并不会影响最终的遍历结果,但是由于聚合操作需要遍历完成整张表,不能遍历到一半就输出聚合结果,万一后面还有与当前字段重复的值呢?再新增到此前得到的结果里去,会极大地增大查询计划的执行难度。
因此,在 Init Aggregation 时,就需要把分组的结果都算出来,而不是像 Task#1 中,可以一条又一条tuple地去 Next 执行。在Init过程中,结果保存到SimpleAggregationHashTable aht_;中,next中利用SimpleAggregationHashTable::Iterator aht_iterator_;来访问即可
注意在实现GenerateInitialAggregateValue函数中,count()的初值设置为0,其余的设置为null
NestedLoopJoin
NestedLoopJoin的核心思想还是比较简单的,伪代码如下:
1 | foreach tuple r in R: (Outer) |
在实现时,主要是注意INIT过程中需要将right_tuple都先保存下来。同时在next()也要记录上一次右表匹配到的位置,否则左表的每一行只会产生一行输出。还需要注意处理left join的空值
NestedIndexJoin
如果查询包含具有 equal 条件的 Join,而且连接的外表在查询条件上具有索引,则使用 NestedIndexJoinPlanNode.
此处的核心思想与NestedLoopJoin类似,但是不需要预先保存right_tuple,只需在利用左表行去匹配右表时,利用索引去查找右表中所匹配的节点,保存他们RID,然后处理即可。
索引的使用方式与IndexScan类似,只需要利用到tree_->ScanKey这个api来查找对应的RID
同时注意Nested Index Join 的 Schema 中只有一个 child,用于传输 Join 中与外表(left table)对应的tuples,而非像 Nested Loop Join 中的有两个子节点
Task #3: Sort + Limit Executors and Top-N Optimization
Sort
ORDER BY 匹配的是没有与索引绑定的键,BusTub 将对ORDER BY 运算符使用 SortPlanNode。
在Init中,与Aggregation的处理类似,需要先将所有的tuple保存下来,然后利用std::sort进行排序即可。排序依据于 order_bys中的keys,如果查询并不包含排序方向,就默认按照 ASC 执行。
1 | std::sort( |
Limit
利用一个变量记录emit了多少个tuple,当大于这个值是,直接返回false
1 | u_int32_t count_ = 0; |
Top-N Optimization
利用优先队列priority_queue来处理tuples,最后将priority_queue里的tuple给push到一个vector中,next()中依次访问这个vector即可。
只是实现这个算子是不够的,还需要我们完成OptimizeSortLimitAsTopN这个优化规则。我们只需遍历plan tree,当遇到limit节点时,判断其孩子节点是否是Sort,如果是Sort,则将这两个节点替换为一个 TopN。还是比较简单的。
Leaderboard Task
具体的要求我就不贴了,简而言之是要我们实现hash join这个算子,实现一系列优化规则,包括但不限于:Join Reorder 、Correctly Pick up Index、Predicate Push-down、 Column Pruning
我仅完成了hash join,优化规则有待后续完成
对于hash join,利用src/include/common/util/hash_util.h 里的 HashValue 函数将 join key hash 为 hash_t 类型,然后把 hash_t 作为键。join key由下面这个api得到
1 | right_join_key = plan_->RightJoinKeyExpression().Evaluate(&tuple, plan_->GetRightPlan()->OutputSchema()); |
Init()中,将right_tuple以right_join_key为键push到哈希表中,随后对于left_child_executor_->Next(&tuple, &rid)得到的左表行,在哈希表中得到与left_join_key匹配的tuples,然后将这些匹配的行压入到一个vector中,在next()访问这个vector即可。
总结
做lab3的时候一度做不下去了,因为源码读的我太痛苦了,还好坚持了下来,最后看到gradescope的成绩也是一整个心情舒畅,希望自己再接再厉吧。
回归到这个lab,自己收获还是很多的,对于Bustub 的架构以及查询计划有了一个深入的了解。
 微信
微信 支付宝
支付宝

