CMU15-445 bustub Project4:Concurrency Control
写在前面
参考资料:
- https://zhuanlan.zhihu.com/p/592700870
- https://www.bilibili.com/video/BV1bQ4y1Y7iT
- https://zhuanlan.zhihu.com/p/592700870
历时整整两个月,总算完成了15445的学习,收获很大,总体上说,project4的难度是比较低的,个人感觉2 >> 3 > 4 ≈ 1。
Project4: Concurrency Control主要是依据lecture中的2PL以及三种事务隔离机制实现一个锁管理器,并且要具备死锁检测的功能。主要分为三个task:
- Lock Manager :锁管理器,利用 2PL 实现并发控制。支持 REPEATABLE_READ、READ_COMMITTED 和 READ_UNCOMMITTED 三种隔离级别,支持 SHARED、EXCLUSIVE、INTENTION_SHARED、INTENTION_EXCLUSIVE 和 SHARED_INTENTION_EXCLUSIVE 五种锁,支持 table 和 row 两种锁粒度,支持锁升级。
- Deadlock Detection:死锁检测,运行在一个 background 线程,每间隔一定时间检测当前是否出现死锁,并挑选合适的事务将其 abort 以解开死锁。
- Concurrent Query Execution:修改之前实现的 SeqScan、Insert 和 Delete 算子,加上适当的锁以实现并发的查询。
一、前置知识
1.1 Serializable
当事务并发时,假如事务并发执行的顺序能够等于这些事务按某种顺序顺序执行的结果,那么称这些事务的并发是 serializable schedule,称这两个 schedule 是 Serializable Schedule。事务并发执行的顺序很难确保说是等价于某种顺序执行,只能依照不同的并发策略而定。
1.2 Two Phase Locking(2PL)
通过并发策略就能够管理事务,是他们自动保证一个 schedule 是 serializable。不难想到,保证 schedule 正确性的方法就是合理的加锁 (locks) 策略,2PL 就是其中之一。
注意:2PL 保证正确性的方式是通过获得锁的顺序实现的,也就说我们没办法强制要求事务按照某个 serial schedule 并发,只能保证最终结果是正确的。
2PL,顾名思义,有两个阶段:growing 和 shrinking:
growing: 事务可以按需获取某条数据的锁,lock manager 决定同意或者拒绝。一旦开始释放锁就进了 shrinking 阶段shrinking:阶段中,事务只能释放之前获取的锁,不能获得新锁,即一旦开始释放锁,之后就只能释放锁。
1.3 Transaction isolation mechanism
按照等级(隔离程度)由低到高:
- Read uncommitted (未提交读)
- Read committed (提交读)
- Repeatable read (可重复读) (mysql默认)
- Serializable (可序列化)
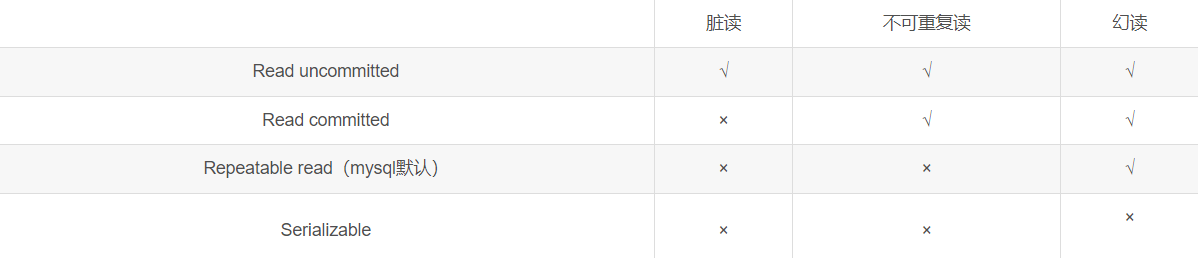
√代表可能出现的问题
注意: 可以采用提高事务的隔离级别的方式来解决脏读、不可重复读、幻读等问题, 但与此同时, 事务的隔离级别越高, 并发能力也就越低; 所以, 还需要读者根据业务需要进行权衡
1.3.1 未提交读 (Read uncommitted)
-
定义
是最低的隔离级别, 在这种事务隔离级别下, 一个事务可以读到另外一个事务未提交的数据 -
数据库加锁情况(实现原理)
事务在读数据的时候并未对数据加锁
事务在修改数据的时候只对数据增加写锁,并在使用完后立即释放 -
现象解释
事务1读取某行记录时, 事务2也能对这行记录进行读取、更新, 并且因为事务一并未对数据增加任何锁
当事务2也对该记录进行更新时, 事务1再次读取该记录, 能读到事务2对该记录的修改版本 (因为事务2只增加了共享读锁, 事务1可以再增加共享读锁读取数据), 即使该修改尚未被提交, 若此时事务2回滚, 那事务1读到的就脏数据了, 这就引发了脏读现象
事务1更新某行记录时, 事务2不能对这行记录做更新, 直到事务1结束 (因为事务1对数据增加了共享读锁, 事务2不能增加排他写锁进行数据的修改)
1.3.2 提交读 (Read committed)
-
定义
可以理解成都已提交, 在一个事务修改数据过程中, 如果事务还没提交, 其他事务不能读该数据 -
数据库加锁情况
事务对当前被读取的数据增加行级共享锁(读到时才加锁), 一旦读完该行, 立即释放该行行级共享锁
事务在更新某数据的瞬间(在更新的瞬间), 必须先对其加行级排它锁, 直到事务结束才释放 -
现象解释
事务1在读取某行记录的整个过程中, 事务2都可以对该行记录进行读取 (因为事务一对该行记录增加行级共享锁的情况下, 事务二同样可以对该数据增加共享锁来读数据)
事务1读取某行的一瞬间, 事务2不能修改该行数据, 但是, 只要事务1读取完改行数据, 事务2就可以对该行数据进行修改 (事务一在读取的一瞬间会对数据增加共享锁, 任何其他事务都不能对该行数据增加排他锁; 但是事务一只要读完该行数据, 就会释放行级共享锁, 一旦锁释放, 事务二就可以对数据增加排他锁并修改数据)
事务1更新某行记录时, 事务2不能对这行记录做更新, 直到事务1结束 (事务一在更新数据的时候, 会对该行数据增加排他锁, 知道事务结束才会释放锁, 所以, 在事务二没有提交之前, 事务一都能不对数据增加共享锁进行数据的读取; 所以, 提交读可以解决脏读的现象)
1.3.3 可重复读 (Repeatable reads)
-
定义
由于提交读隔离级别会产生不可重复读的读现象, 所以比提交读更高一个级别的隔离级别就可以解决不可重复读的问题, 这种隔离级别就叫可重复读 -
数据库锁情况
事务在读取某数据的瞬间 (就是开始读取的瞬间), 必须先对其加行级共享锁, 直到事务结束才释放
事务在更新某数据的瞬间 (就是发生更新的瞬间), 必须先对其加行级排他锁, 直到事务结束才释放 -
现象解释
事务1在读取某行记录的整个过程中, 事务2都可以对该行记录进行读取 (因为事务一对该行记录增加行级共享锁的情况下, 事务二同样可以对该数据增加共享锁来读数据)
事务1在读取某行记录的整个过程中, 事务2都不能修改该行数据 (事务一在读取的整个过程会对数据增加共享锁, 直到事务提交才会释放锁, 所以整个过程中, 任何其他事务都不能对该行数据增加排他锁; 所以, 可重复读能够解决不可重复读的读现象)
事务1更新某行记录时, 事务2不能对这行记录做更新, 直到事务1结束 (事务一在更新数据的时候, 会对该行数据增加排他锁, 知道事务结束才会释放锁, 所以, 在事务二没有提交之前, 事务一都能不对数据增加共享锁进行数据的读取; 所以, 提交读可以解决脏读的现象)
1.3.4 可序列化 (Serializable)
-
定义
是最高的隔离级别, 前面三种隔离级别都无法解决的幻读, 在可序列化的隔离级别中可以解决 -
数据库锁情况
事务在读取数据时, 必须先对其加表级共享锁, 直到事务结束才释放
事务在更新数据时, 必须先对其加表级排他锁, 直到事务结束才释放 -
现象解释
事务1正在读取A表中的记录时, 则事务2也能读取A表, 但不能对A表做更新、新增、删除, 直到事务1结束 (因为事务一对表增加了表级共享锁, 其他事务只能增加共享锁读取数据, 不能进行其他任何操作)
事务1正在更新A表中的记录时, 则事务2不能读取A表的任意记录, 更不可能对A表做更新、新增、删除, 直到事务1结束 (事务一对表增加了表级排他锁, 其他事务不能对表增加共享锁或排他锁, 也就无法进行任何操作) -
序列化事务产生的效果:
-
- 无法读取其他事务已经修改单位提交的记录
-
- 在当前事务完成之前, 其他事务不能修改当前事务已经读取的记录
-
- 在当前事务完成之前, 其他事务插入的新记录, 其索引键值不能在当前事务的任何语句所读取的索引键范围中
在本项目中,并不涉及可序列化这一隔离级别,因此我们只需关注前三种隔离级别即可。
二、Lock Manager
Lock Manager 的结构:

Lock Manager 的作用是处理事务发送的锁请求,例如有一个 SeqScan 算子需要扫描某张表,其所在事务就需要对这张表加 S 锁。而加读锁这个动作需要由 Lock Manager 来完成。事务先对向 Lock Manager 发起加 S 锁请求,Lock Manager 对请求进行处理。如果发现此时没有其他的锁与这个请求冲突,则授予其 S 锁并返回。如果存在冲突,例如其他事务持有这张表的 X 锁,则 Lock Manager 会阻塞此请求(即阻塞此事务),直到能够授予 S 锁,再授予并返回。
2.1 Lock
1.检查事务的状态:
若 txn 处于 Abort/Commit 状态,抛逻辑异常,不应该有这种情况出现。
若 txn 处于 Shrinking 状态,则需要检查 txn 的隔离级别是否允许当前锁请求类型:
- READ_UNCOMMITTE 隔离级别中只允许使用X和IX锁(即只加写锁)
- READ_UNCOMMITTE 隔离级别下收缩状态下不允许获得X和IX锁(写锁)
- READ_COMMITTED 隔离级别在收缩状态下只允许使用IS、S锁(即读锁)
- REPEATABLE_READ 隔离级别在收缩状态下不允许使用锁
如果是对row加锁,要注意不能加意向锁,同时要检查是否持有 row 对应的 table lock。
2.从map处获取对应的lock_request_queue
从 table_lock_map_ 中获取 table 对应的 lock request queue。注意需要对 map 加锁,并且为了提高并发性,在获取到 queue 之后立即释放 map 的锁。若 queue 不存在则创建。
3.检查锁请求是否为锁升级
- 遍历队列查看有没有与当前事务 id 相同的请求。如果存在这样的请求,则代表当前事务在此前已经得到了在此资源上的一把锁,接下来可能需要锁升级
- 判断此前授予锁类型是否与当前请求锁类型相同。若相同,则代表是一次重复的请求,直接返回。否则进行下一步检查。
- 判断当前资源上是否有另一个事务正在尝试升级(queue->upgrading_ == INVALID_TXN_ID)。若有,则终止当前事务,抛出 UPGRADE_CONFLICT 异常。因为不允许多个事务在同一资源上同时尝试锁升级。
- 判断升级锁的类型和之前锁是否兼容,不能反向升级。允许的升级规则:IS -> [S, X, IX, SIX] ,S -> [X, SIX], IX -> [X, SIX], SIX -> [X]
- 进行锁升级。
-
- 释放当前已经持有的锁,包括lock_manager中的锁记录和事务中的锁记录。
-
- 升级的锁作为一个新的请求加入队列,插入的位置是当前第一个没有被授予的锁的位置。这里插入的位置是根据优先级规则来确定的。如果队列中存在锁升级请求,若锁升级请求正为当前请求,则优先级最高。否则代表其他事务正在尝试锁升级,优先级高于当前请求。若队列中不存在锁升级请求,则遍历队列。如果,当前请求是第一个 waiting 状态的请求,则代表优先级最高。如果当前请求前面还存在其他 waiting 请求,则要判断当前请求是否前面的 waiting 请求兼容。若兼容,则仍可以视为优先级最高。若存在不兼容的请求,则优先级不为最高。
-
- 并在 queue 中标记当前事务正在尝试升级
- 若不是锁升级,则为平凡的锁请求,加入到request_queue_即可,在此处可以将 LockRequest的裸指针优化为智能指针。
4.尝试获取锁
1 | //等待直到新锁被授予。 |
GrantLock()判断锁请求lock_request是否可被授予。依次判断lock_request_queue中已经授予的锁是否和当前向获取的锁冲突,当全部不冲突才返回true,只要队列中有任意一个granted的锁与当前请求的锁冲突,则false。
2.2 Unlock
Unlock的逻辑比较简单
- 确保当前事务中持有该表的锁
- table lock,在释放时需要先检查其下的所有 row lock 是否已经释放。
- 获取对应的 lock_request_queue
- 遍历请求队列,找到 unlock 对应的 granted 请求
- 在锁成功释放后,调用 cv_.notify_all() 唤醒所有阻塞在此 table 上的事务
- 找到对应的请求后,根据事务的隔离级别和锁类型修改其状态。
-
- 当隔离级别为 REPEATABLE_READ 时,S/X 锁释放会使事务进入 Shrinking 状态。
-
- 当为 READ_COMMITTED 时,只有 X 锁释放使事务进入 Shrinking 状态。
-
- 当为 READ_UNCOMMITTED 时,X 锁释放使事务 Shrinking,S 锁不会出现。
二、Deadlock Detection
-
此task利用一个unordered_map类型的waits_for_来表示事务之间的等待关系。wait for 是一个有向图,t1->t2 即代表 t1 事务正在等待 t2 事务释放资源。当 wait for 图中存在环时,即代表出现死锁,需要挑选事务终止以打破死锁。
-
我们并不需要时刻维护 wait for 图,而是在死锁检测线程被唤醒时,根据当前请求队列构建 wait for 图,再通过 wait for 图判断是否存在死锁。当判断完成后,将丢弃当前 wait for 图。下次线程被唤醒时再重新构建。
-
最常见的有向图环检测算法包括 DFS 和拓扑排序。在这里我们选用 DFS 来进行环检测。构建 wait for 图时要保证搜索的确定性。始终从 tid 较小的节点开始搜索,在选择邻居时,也要优先搜索 tid 较小的邻居。
-
构建 wait for 图的过程是,遍历 table_lock_map 和 row_lock_map 中所有的请求队列,对于每一个请求队列,用一个二重循环将所有满足等待关系的一对 tid 加入 wait for 图的边集。满足等待关系是指,对于两个事务 a 和 b,a 是 waiting 请求,b 是 granted 请求,则生成 a->b 一条边。
-
在发现环后,我们可以得到环上的所有节点。此时我们挑选 youngest 的事务将其终止。youngest 的事务即是tid 最大的事务。
-
挑选出 youngest 事务后,将此事务的状态设为 Aborted。并且在请求队列中移除此事务,释放其持有的锁,终止其正在阻塞的请求,并调用 cv_.notify_all() 通知正在阻塞的相关事务。此外,还需移除 wait for 图中与此事务有关的边。不是不用维护 wait for 图,每次使用重新构建吗?这是因为图中可能存在多个环,不是打破一个环就可以直接返回了。需要在死锁检测线程醒来的时候打破当前存在的所有环。
三、Concurrent Query Execution
此task是对查询执行的tuple进行并发控制,即对最基本三种算子SeqScan、Insert、Delete进行修改以满足并发控制。
3.1 SeqScan
- 在初始化时 Init()中 进行并发控制,在 READ_UNCOMMITTED 下不用加锁,其余两种隔离级别下需要加锁,需先给表加IS锁
- 利用迭代器遍历时 Next()中 对行加锁,并且在遍历到结尾时释放锁,在 READ_COMMITTED 下,在 Next() 函数中,若表中已经没有数据,则提前释放之前持有的锁。在 REPEATABLE_READ 下,在 Commit/Abort 时统一释放,无需手动释放。并且先释放行锁再释放表锁。
- 实现一个
Predicate pushdown to SeqScan的优化,即将 Filter 算子结合进 SeqScan 里,这样我们仅需给符合 predicate 的行加上 S 锁,减小加锁数量。利用这个while循环实现: -
while (plan_->filter_predicate_ != nullptr && !plan_->filter_predicate_->Evaluate(tuple, table_info_->schema_).GetAs<bool>());
3.2 Insert & Delete
- Insert & Delete 的操作类似,在 Init() 函数中,为表加上 IX 锁,在Next() 中为行加 X 锁。
- 若获取失败则抛 ExecutionException 异常。另外,这里的获取失败不仅是结果返回 false,还有可能是抛出了 TransactionAbort() 异常,例如 UPGRADE_CONFLICT,需要用 try catch 捕获。
四、Leaderboard Task
4.1 Predicate Pushdown to SeqScan
在第三节已经讲过此优化,即将 Filter 算子结合进 SeqScan 里,这样我们仅需给符合 predicate 的行加上 S 锁,减小加锁数量。利用一个while循环实现:while (plan_->filter_predicate_ != nullptr && !plan_->filter_predicate_->Evaluate(tuple, table_info_->schema_).GetAs<bool>());
4.2 Implement UpdateExecutor
实现Update这个算子,这样可以在原地直接修改 tuple,不需要先 Delete 再 Insert。利用tableheap中的UpdateTuple这个api实现即可,注意表加 IX 锁,行加 X 锁。返回更新的行的数量。
4.3 Use Index
修改IndexScan这个算子以让他满足并发控制,利用索引能大幅提高查询效率。具体做法是修改 IndexScan 算子,添加一种单点查询的情况。并在优化规则中尝试匹配形如
1 | Filter |
的情况,并且 Filter 的 Predicate 形如 x=a,其中 x 是 ColumnValue,x 上有索引,a 是 ConstantValue。注意这条优化规则要在 MergeFilterScan 之前执行,否则 Filter 会直接被 Merge 到 SeqScan 里了。或者直接优化已经完成 Merge 的 SeqScan 算子。
在成功匹配后,提取出 a,并将查询计划更新为执行索引单点查询的 IndexScan 算子,使用 ScanKey(tuple{a}) 查询,需要构造一下包含 a 的 tuple。同样,单点查询时IndexScan 算子中要注意加锁,表 IS 行 S。
总结
期间由于学业和各种原因断断续续的将近2个月才完成15445,但是收获的东西却比整个学期学校安排的课还多。感谢Andy和各位助教设计了此课程,下一步就是转战6.824了。
 微信
微信 支付宝
支付宝

